What is Retrieval-Augmented Generation (RAG)?

The RAG (Retrieval-Augmented Generation) system, which traces information and recreates it from scratch, is redefining the boundaries of artificial intelligence.
RAG (Retrieval-Augmented Generation): Find and Generate Information
In recent years, RAG (Retrieval-Augmented Generation) has emerged as an innovative method that pushes the boundaries of language models. The primary goal of RAG is quite clear: instead of being limited to the information it has been trained on, it retrieves external data sources (retrieval) and uses this data to generate (generation) natural and fluent responses. In an era where large language models dominate, it is no surprise that hybrid systems like RAG are also becoming increasingly popular.
In this article, I will cover what RAG is, how the system works, and the tools that can be used for its implementation.
What is RAG? Why is it Important?
RAG (Retrieval-Augmented Generation) provides a two-step approach that allows language models to go beyond their training data:
- Retrieval (Information Access)
- Generation (Text Creation)
Traditional language models generate responses solely based on the data they have been trained on. RAG, however, can access external data sources (such as Wikipedia and proprietary company documents) to continuously use up-to-date information. This enables the model to retrieve real-time information that was not part of its training and incorporate it into the generation phase. As a result, it increases the likelihood of obtaining accurate answers, especially for dynamic topics or recent developments.
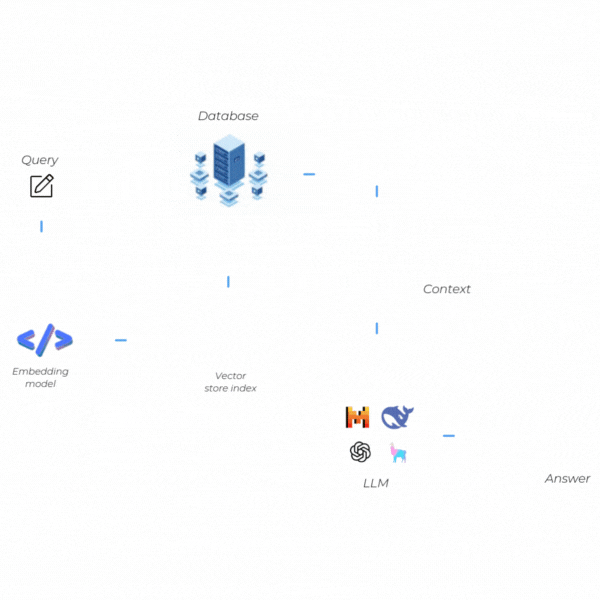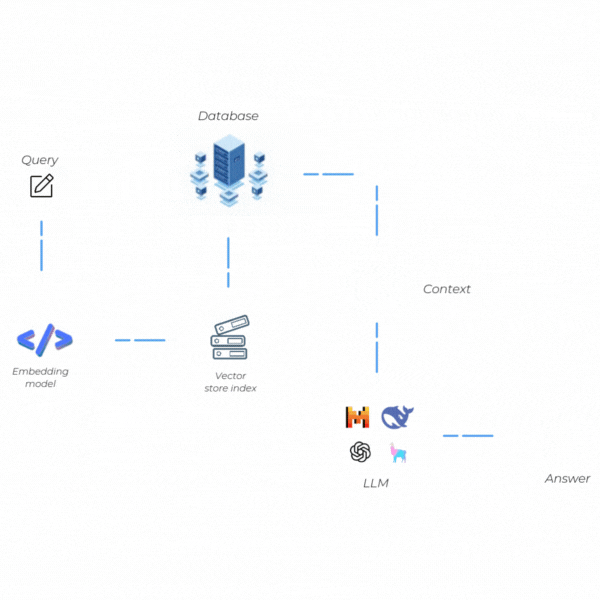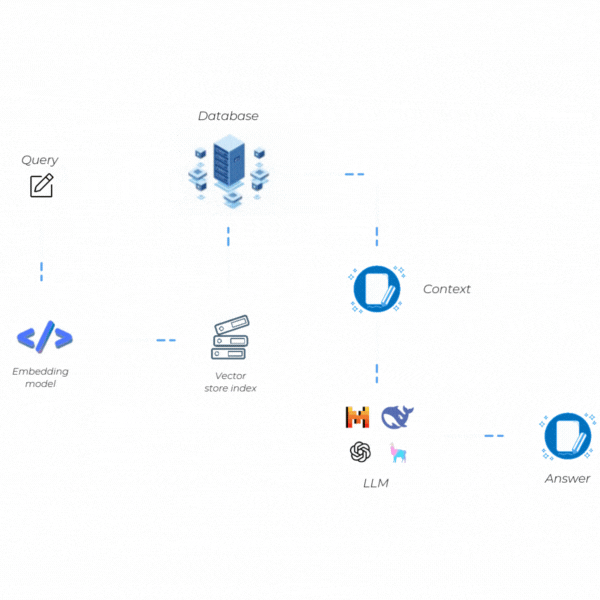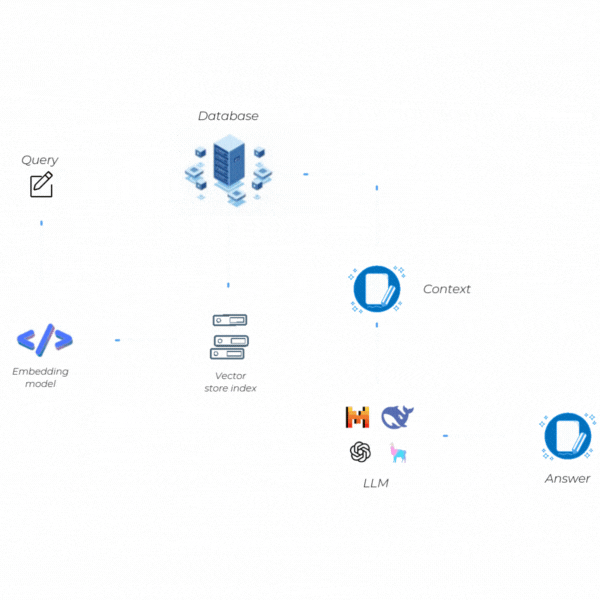
How Does RAG Work?
The functioning of RAG is based on the seamless integration of two key stages: Retrieval (Information Access) and Generation (Text Creation). These stages are interconnected, and each aims to provide high-quality responses with both up-to-date and verifiable information. Let's take a quick look at these two steps.
Retrieval (Information Access)
-
Query Analysis and Embedding:
When a user asks a question or inputs text, the first step is to generate a numerical representation (embedding) of the query. Transformer-based models or different text embedding techniques (such as Sentence-BERT) can be used for this purpose. The obtained query embedding compactly and comparably represents the actual meaning of the query.
-
Vector Database Comparison:
The query embedding is sent to vector databases such as FAISS, Pinecone, Weaviate, or Qdrant. These databases store pre-indexed document embeddings.
- Indexed document embeddings are obtained through preprocessing various text sources (Wikipedia articles, company documents, research reports, etc.).
- The query embedding is compared with document embeddings using similarity measures such as cosine similarity or dot product. This allows the system to quickly find the most relevant documents (i.e., text passages that are semantically closest to the query).
-
Selection of Relevant Documents:
Once the relevant documents for the query are determined, the system selects the top-ranked text passages. These passages are then transferred to the next stage, the Generation phase.
Generation (Text Creation)
-
Providing Input to the LLM:
The retrieved documents, along with the original user query, are fed into a large language model (such as GPT, LLaMA, Mistral, Gemini). This model reads the text passages in the input and attempts to determine which sections are important.
-
Contextual Processing and Response Generation:
The model evaluates the retrieved documents and the query holistically. The goal is to generate a response that is semantically coherent, understandable, and supported by relevant information sources. The generated response is then presented to the user as output.
Simulating a RAG Query
-
User Query (Input):
How do quantum computers work differently from classical computers?
-
Query Analysis and Embedding:
The query is converted into an embedding using an embedding model (e.g., bge-base-en). Vector: [0.23, -0.87, 0.45, ...]
-
Vector Database Search:
A cosine similarity comparison is performed with document embeddings stored in Qdrant. The top 3 most similar documents are selected:
- Document: "Quantum Superposition and Entanglement..." (0.91 score)
- Document: "Classical Computers Use Bit-Based Processing..." (0.87 score)
- Document: "Quantum Gates and Computational Logic..." (0.85 score)
-
Sending Selected Documents to the LLM:
The user query and relevant document passages are provided as context to a large language model (e.g., GPT-4, LLaMA3).
-
Model Response:
"Quantum computers differ from classical computers in that they utilize quantum mechanical principles such as superposition and entanglement. While classical computers process data using bits (0s and 1s), quantum computers use quantum bits (qubits). Qubits, through superposition, can exist as both 0 and 1 simultaneously, providing an exponential computational advantage for specific tasks. Additionally, quantum entanglement allows qubits to be correlated across distances, enabling near-instantaneous information sharing. These properties make quantum computers significantly faster in solving problems like prime factorization and optimization compared to classical systems."
Advantages and Disadvantages of RAG
Advantages
- Access to Up-to-Date Information: Unlike traditional models that rely only on training data, RAG can retrieve and integrate the latest information from external sources.
- Accuracy and Consistency: By referencing extensive information sources, RAG can generate more precise responses, particularly for complex or niche subjects.
- Scalability: Instead of retraining the model for new data, RAG only requires updating the indexed retrieval layer.
- Specialized Applications: RAG can be tailored to specific fields such as medicine, law, or engineering by incorporating domain-specific documents.
Disadvantages
- Data Reliability: If the indexed documents contain incorrect or irrelevant information, the model may generate unreliable responses, potentially increasing "hallucination" risks.
- Cost and Maintenance: Vector databases, indexing processes, and system maintenance can be resource-intensive. Keeping the model updated and maintaining the retrieval database can become complex for large-scale projects.
- Data Security and Privacy: When accessing external sources, additional security measures (encryption, authorization, etc.) must be implemented to protect sensitive data.
- Consistency: When different sources contain conflicting information, the model must prioritize which data to use. Without a robust validation or confidence scoring mechanism, response consistency may be compromised.
Real-World Applications of RAG
- Internal Company Knowledge System: Indexes all company documents to provide employees with instant, accurate, and customized responses via a chatbot.
- E-Commerce Customer Support: Searches product descriptions, user reviews, and FAQs to deliver quick and relevant responses to customers.
- News Analysis and Content Verification: Analyzes real-time data from social media or news sources to reduce misinformation.
- Legal Assistance and Document Analysis: Law firms index court decisions, legal documents and legislation, allowing lawyers to quickly find the right information. It suggests past judicial decisions or relevant articles of law for a case.
- Education and Research Support: Universities or e-learning platforms provide customized information to students and researchers by indexing scholarly publications, lecture notes and research materials. It can provide a resource-backed answer to a specific academic question a student asks.
- Financial Analysis and Reporting: Banks and investment firms support investors or analysts to make faster decisions by indexing market reports, stock analysis and financial regulations. It can provide summary information about the company's past performance.
Summary
RAG represents a significant advancement in AI-driven information retrieval and response generation. When implemented correctly, it can serve as a powerful tool for solving complex problems with high reliability and efficiency. However, its success depends heavily on the accuracy and timeliness of the data sources it retrieves from. Therefore, careful data management and the selection of appropriate retrieval tools are crucial for an effective RAG system.
Useful Resources
Here you can check benchmarks of embedding models. You need to select features such as "number of parameters" and "embedding dimensions" in Benchmark according to your project. The more of these features you have, the more storage space and response time you need. In addition, models developed for specific uses (for example, indexing data in the field of health) will also increase your accuracy rates within the scope of the project.
Popular Vector Databases
- Qdrant
- Milvus
- Pinecone
- Weaviate
- LanceDB
- Chroma