Retrieval Augmented Generation (RAG) Nedir?

Bilginin izini sürüp onu baştan yaratan RAG (Retrieval-Augmented Generation), yapay zekanın sınırlarını yeniden çiziyor.
RAG (Retrieval-Augmented Generation): Bilgiyi Bul ve Üret
Yapay zeka alanında son yıllarda adını sıkça duymaya başladığımız RAG (Retrieval-Augmented Generation), dil modellerinin ulaştığı noktayı bir adım öteye taşıyan yenilikçi bir yöntem. RAG’ın temel amacı oldukça net: Sadece önceden öğrendiği bilgilerle sınırlı kalmayıp, harici kaynaklardan da veri çekerek (retrieval), bu verileri kullanıp (generation) doğal ve akıcı yanıtlar üretmek. Büyük dil modellerinin gözde olduğu bu dönemde, RAG gibi hibrit sistemlerin de popüler hale gelmesi hiç şaşırtıcı değil.
Bu yazıda RAG'ın ne olduğu, sistemin çalışma mantığı, kullanılabilecek araçlar gibi bir çok konuya değinmeye çalışacağım.
RAG Nedir? RAG Kullanmak Neden Önemlidir?
RAG (Retrieval-Augmented Generation), dil modellerinin eğitim verilerinin ötesine geçmesini sağlayan iki aşamalı bir yaklaşım sunar:
- Bilgi Erişim (Retrieval)
- Metin Üretimi (Generation)
Geleneksel dil modelleri, yalnızca kendilerine öğretilen veriler doğrultusunda yanıtlar üretir. RAG ise harici veri kaynaklarına erişerek (örneğin Wikipedia ve özel şirket dokümanları) sürekli güncel bilgileri kullanabilir. Bu sayede, model eğitim sırasında yer almayan bilgileri bile anlık olarak çekerek metin üretimi aşamasında kullanır. Özellikle değişken konularda veya yeni gelişmelerde doğru yanıtlara ulaşma olasılığı artar.
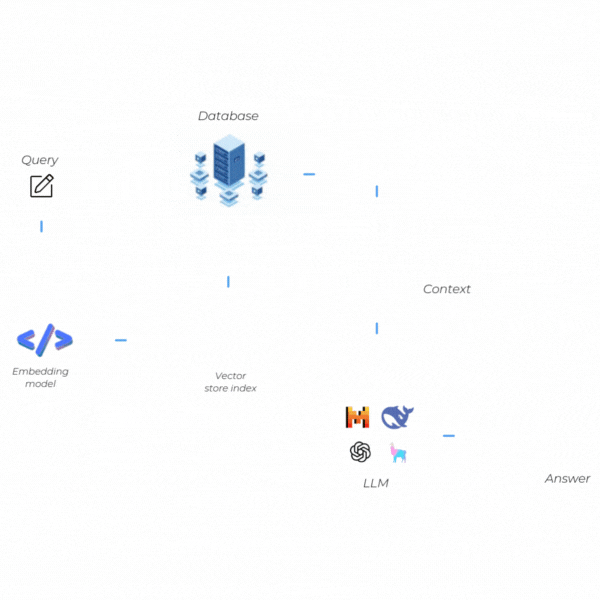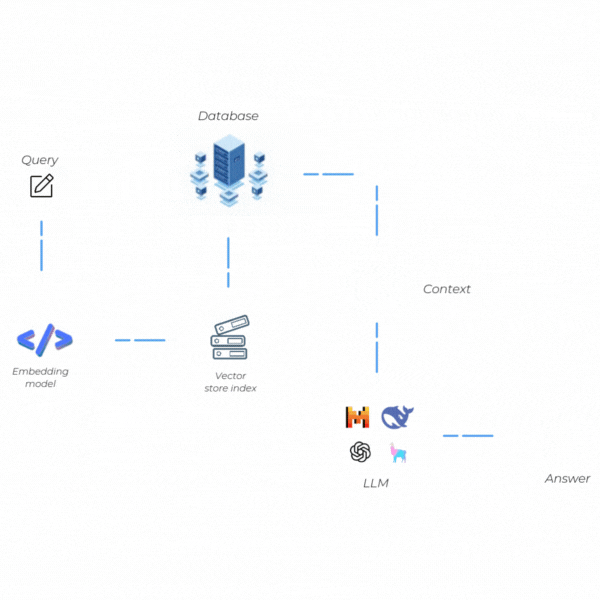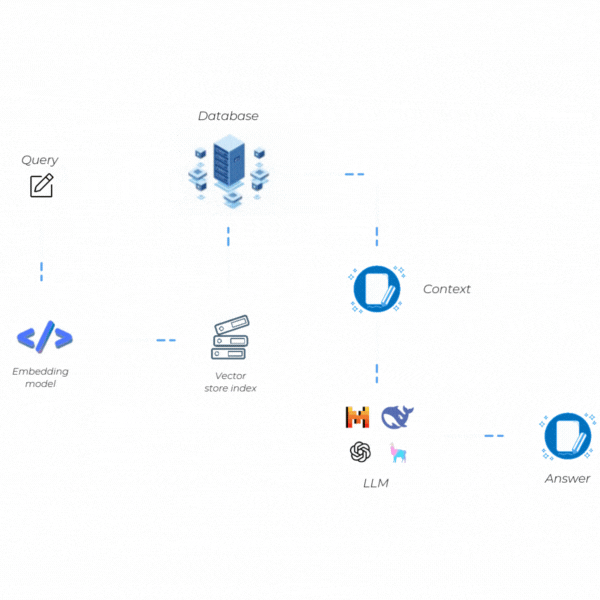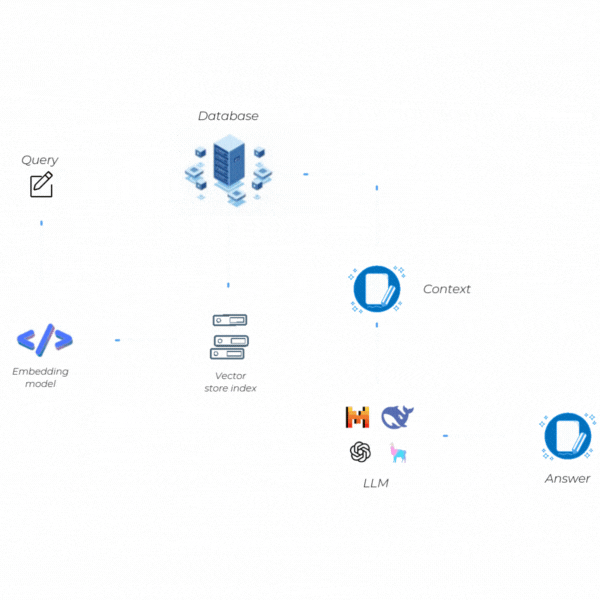
RAG Nasıl Çalışır?
RAG’in işleyişi, iki temel aşamanın uyumlu bir şekilde bir araya gelmesiyle gerçekleşir: Retrieval (Bilgi Erişim) ve Generation (Metin Üretimi). Bu aşamalar birbirine bağlıdır ve her biri, sistemin hem güncel hem de doğrulanabilir bilgilerle kaliteli yanıtlar vermesini amaçlar. Şimdi bu iki adımda neler yaptığımıza kısaca bir göz atalım.
Retrieval (Bilgi Erişim)
-
Sorgu Analizi ve Embedding:
Kullanıcı bir soru sorduğunda veya bir metin girdiğinde, ilk adım bu sorgunun sayısal bir temsilini (embedding) oluşturmaktır. Burada transformer tabanlı modeller veya farklı metin gömme teknikleri (örneğin, Sentence-BERT gibi) kullanılabilir. Elde edilen sorgu embedding’i, sorgunun asıl anlamını kompakt ve kıyaslanabilir bir biçimde temsil eder.
-
Vektör Veritabanı ile Karşılaştırma:
Sorgu embedding’i, FAISS, Pinecone, Weaviate veya Qdrant gibi vektör tabanlı veritabanlarına (vector databases) gönderilir. Bu veritabanları, daha önce indekslenmiş doküman embedding’lerini barındırır.
- İndekslenmiş doküman embedding’leri, herhangi bir metin kaynağından (Wikipedia makaleleri, şirket dokümanları, araştırma raporları vb.) ön işlemden geçirilerek elde edilir.
- Sorgu embedding’i, doküman embedding’leriyle cosine similarity, dot product veya benzeri benzerlik ölçümleri kullanılarak kıyaslanır. Bu sayede en benzer dokümanlar (yani, sorguyla semantik olarak en ilişkili metin parçaları) hızlıca bulunur.
-
Uygun Dokümanların Seçimi:
Sorguyla ilgili olan dokümanlar belirlendikten sonra, bu dokümanlar arasından en çok benzerlik gösteren belirli sayıda metin parçası seçilir. Bu parçalar, bir sonraki aşama olan Generation kısmına aktarılır.
Generation (Metin Üretimi)
-
LLM'e Girdi Verme:
Retrieval aşamasında seçilen dokümanlar, asıl sorguyla birlikte bir büyük dil modeline (GPT, LLaMA, Mistral, Gemini vb.) girdi olarak beslenir. Bu model, girdideki metin parçalarını okur ve hangi bölümlerin önemli olduğunu belirlemeye çalışır.
-
Bağlamsal İşleme ve Yanıt Oluşturma:
Model, aldığı belgelerin içeriğini ve sorguyu bütüncül bir şekilde değerlendirir. Amaç, kullanıcıya anlamsal olarak tutarlı, anlaşılır ve kaynak bilgilerle desteklenmiş bir yanıt üretmektir. Üretilen yanıt kullanıcıya çıktı olarak verilir.
Bir RAG Sorgusunu Simüle Edelim
-
Kullanıcı Sorgusu (Input, Girdi):
Kuantum bilgisayarlar klasik bilgisayarlardan nasıl farklı çalışır?
-
Sorgu Analizi ve Embedding:
Sorgu, embedding modeli (örn: bge-base-en) ile embedding'e dönüştürülür. Vektör: [0.23, -0.87, 0.45, ...]
-
Vektör Veritabanında Arama:
Qdrant içinde depolanmış doküman embedding'leriyle cosine similarity karşılaştırması yapılır. En benzer 3 doküman seçildi: - Doküman: "Kuantum süperpozisyon ve dolanıklık..." (0.91 skor) - Doküman: "Klasik bilgisayarlar bit temelli çalışır..." (0.87 skor) - Doküman: "Kuantum kapıları ve işlem mantığı..." (0.85 skor)
-
Seçilen Dokümanların LLM'e Gönderilmesi:
Kullanıcı sorgusu ve ilgili doküman parçaları, büyük dil modeline (örn: GPT-4, LLaMA3) bağlam olarak verilir.
-
Model Yanıtı:
"Kuantum bilgisayarlar, klasik bilgisayarların bit temelli hesaplamalarından farklı olarak, süperpozisyon ve dolanıklık gibi kuantum mekaniği prensiplerini kullanır. Klasik bilgisayarlar veriyi 0 ve 1 bitleri ile işlerken, kuantum bilgisayarlar qubit adı verilen veri birimlerini kullanır. Qubit'ler, süperpozisyon sayesinde aynı anda hem 0 hem de 1 olabilir, bu da belirli hesaplamalarda üstel hız avantajı sağlar. Ayrıca, kuantum dolanıklık sayesinde, birbirine bağlı qubit'ler arasında anında bilgi paylaşımı gerçekleşebilir. Bu özellikler, belirli problemlerin (örneğin, büyük sayıların çarpanlarına ayrılması, optimizasyon) klasik bilgisayarlardan çok daha hızlı çözülmesini mümkün kılar."
RAG'ın Avantaj ve Dezavantajları
Avantajları
- Güncel Veriye Erişim: Geleneksel modeller yalnızca eğitim sürecinde gördükleri verilerle sınırlıyken, RAG harici veri tabanlarından yeni veya güncel bilgiyi anında çekebilir.
- Doğruluk ve Tutarlılık: Kapsamlı bir bilgi kaynağına başvurarak, özellikle karmaşık veya niş konularda daha doğru yanıtlar verebilir.
- Ölçeklenebilirlik: Yeni veriler geldikçe modelin eğitilmesi yerine, sadece retrieval katmanındaki indeksleme güncellenir.
- Spesifik Alanlarda Kullanım: Tıp, hukuk veya mühendislik gibi uzmanlık gerektiren alanlarda, ilgili dokümanların eklenmesiyle sistem hızla özel bir bilgi kaynağına dönüşebilir.
Dezavantajları
- Veri Güvenilirliği: Sisteme verilen dokümanlar yanlış veya alakasızsa, model güvenilir olmayan bilgilerle sonuç üretebilir. Bu durumda RAG'ın azaltmasını beklediğimiz "hallucination" riskini artırabilir.
- Maliyet ve Yönetim: Vektör veritabanları, indeksleme süreçleri ve sistem yönetimi gibi konular maliyet olarak karşımıza çıkar. Modeli canlı tutmak için gerekli güncellemeler ve veritabanı bakımı, özellikle büyük miktarda veriye sahip projelerde yönetilmesi zor bir hal alabilir.
- Veri Güvenliği ve Gizlilik: Harici kaynaklara erişme sürecinde hassas verilerin korunması için ek güvenlik önlemleri (şifreleme, yetkilendirme vb.) alınmalıdır.
- Tutarlılık: Farklı kaynakların çelişkili bilgiler içermesi durumunda, modelin hangi veriye öncelik vereceği belirlenmelidir. İyi bir doğrulama veya güven skoru mekanizması kurulmadığı takdirde, yanıtların tutarlılığından ödün verilebilir.
RAG’i Hangi Gerçek Hayat Problemlerinde Kullanıyoruz / Kullanabiliriz?
- Şirket İçi Bilgi Sistemi: Tüm kurum dokümanlarını indeksleyerek çalışanların sorularına anlık, doğru ve özelleştirilmiş yanıtlar sunan bir chatbot.
- E-Ticaret Müşteri Desteği: Ürün açıklamaları, kullanıcı yorumları veya sıkça sorulan sorular üzerinden arama yapıp müşteriye hızlı ve ilgili sonuçlar sunmak.
- Haber Analizi ve İçerik Doğrulama: Sosyal medya veya haber sitelerinden toplanan verilerle gerçek zamanlı analiz yaparak yanlış bilgilendirmeyi azaltmak.
- Hukuki Destek ve Doküman Analizi: Hukuk firmaları, mahkeme kararlarını, yasal dokümanları ve mevzuatları indeksleyerek avukatların hızlı bir şekilde doğru bilgileri bulmasını sağlar. Bir dava için geçmiş yargı kararlarını veya ilgili yasa maddelerini önerir.
- Eğitim Teknolojileri ve Araştırma Yardımcıları: Üniversiteler veya e-öğrenme platformları, bilimsel yayınları, ders notlarını ve araştırma materyallerini indeksleyerek öğrenci ve araştırmacılara özelleştirilmiş bilgi sağlar. Bir öğrencinin sorduğu spesifik bir akademik soruya kaynaklarla desteklenmiş bir yanıt sunabilir.
- Finansal Analiz ve Raporlama: Bankalar ve yatırım firmaları, piyasa raporları, hisse analizi ve finansal düzenlemeleri indeksleyerek yatırımcıların veya analistlerin daha hızlı karar almasını destekler. Şirketin geçmiş performansı ile ilgili özet bilgi sunabilir.
Konuyu Özetleyelim
RAG, günümüzün hızlı bilgiye erişim ihtiyacını karşılamak ve doğal dil işleme modellerinin sınırlarını genişletmek için büyük bir potansiyel taşır. Doğru uygulandığında, karmaşık problemlerin çözümünde hem güvenilir hem de verimli bir araç olabilir. Ancak sistemin başarısı, kullanılan veri kaynaklarının doğruluğu ve güncelliğine büyük ölçüde bağlıdır. Bu nedenle, RAG mimarisini uygularken veri yönetimi, uygun araçların seçilmesi gibi konulara dikkat etmemiz gerekiyor.
Yararlanabileceğiniz Kaynaklar
Buradan embedding modellerinin başarı oranlarına bakabilirsiniz. Benchmark'ta yer alan "number of parameters", "embedding dimensions" gibi özellikleri kendi projenize uygun olarak seçmeniz gerekiyor. Bu özelliklerin artması, kullandığınız depolama alanının ve yanıt süresinin de artması anlamına geliyor. Bunun dışında özel kullanımlar için geliştirilen (örneğin sağlık alanındaki verilerin indekslenmesi) modeller de proje kapsamında doğruluk oranlarınızı artıracaktır.
Vektör Veri Tabanları
- Qdrant
- Milvus
- Pinecone
- Weaviate
- LanceDB
- Chroma